 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards 3D-Aware Video Diffusion Models: Render-Free Human Motion Control with Mesh Tokenization
Jun 01, 2026Diffusion models have shown remarkable success in video generation. However, whether such models are truly aware of the 3D structure underlying visual observations, rather than simply reproducing plausible 2D projections, remains an open question. In this work, we investigate this question through human motion control, a task that requires precise modelling of 3D human geometry, motion, camera viewpoint, and scene context. Unlike prior methods that rely on rendered 2D motion guidance videos, we propose a render-free framework that conditions video generation directly on compressed 3D human mesh tokens. This representation preserves full 3D geometric information while enabling a unified token-based generation pipeline that processes video tokens jointly with motion tokens in a DiT-based architecture. This design requires the model to reason jointly about appearance, 3D structure, and camera viewpoint during video generation. Experimental results demonstrate strong performance on human motion control benchmarks, while reducing artifacts induced by view-dependent 2D guidance and trajectory-pose mismatches during editing. These findings suggest that video diffusion models, when equipped with mesh tokenization, can better capture complex 3D human structures and their interactions with the surrounding environment.
Lumos-Nexus: Efficient Frequency Bridging with Homogeneous Latent Space for Video Unified Models
May 29, 2026Connector-based video unified models have demonstrated strong capability in instruction-grounded video synthesis, but integrating a large high-fidelity generator into the unified training loop is computationally prohibitive, limiting achievable visual quality. We therefore propose Lumos-Nexus, a training-efficient unified video generation framework that facilitates the development of strong reasoning-driven generation capabilities while significantly enhancing visual fidelity. Lumos-Nexus adopts a two-stage design: 1) During training, only a lightweight generator is aligned with the understanding block to learn to take in reasoning-driven semantic control. 2) During inference, we introduce Unified Progressive Frequency Bridging (UPFB) to progressively hand off generation to a high-capacity pretrained generator in the shared latent space, enabling coarse-to-fine refinement and producing high-fidelity videos without compromising reasoning quality. To fill the gap in reasoning-driven video generation benchmarks, we introduce VR-Bench, which assesses a model's capability to translate inferred intent into coherent and semantically aligned video content. Extensive experiments demonstrate that Lumos-Nexus achieves substantial gains in visual realism and temporal coherence on VBench, while exhibiting strong reasoning-based generative performance on VR-Bench. Code and models are available at https://jiazheng-xing.github.io/nexus-lumos-home/.
LumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
Mar 20, 2026Recent advances in diffusion models have significantly improved text-to-video generation, enabling personalized content creation with fine-grained control over both foreground and background elements. However, precise face-attribute alignment across subjects remains challenging, as existing methods lack explicit mechanisms to ensure intra-group consistency. Addressing this gap requires both explicit modeling strategies and face-attribute-aware data resources. We therefore propose LumosX, a framework that advances both data and model design. On the data side, a tailored collection pipeline orchestrates captions and visual cues from independent videos, while multimodal large language models (MLLMs) infer and assign subject-specific dependencies. These extracted relational priors impose a finer-grained structure that amplifies the expressive control of personalized video generation and enables the construction of a comprehensive benchmark. On the modeling side, Relational Self-Attention and Relational Cross-Attention intertwine position-aware embeddings with refined attention dynamics to inscribe explicit subject-attribute dependencies, enforcing disciplined intra-group cohesion and amplifying the separation between distinct subject clusters. Comprehensive evaluations on our benchmark demonstrate that LumosX achieves state-of-the-art performance in fine-grained, identity-consistent, and semantically aligned personalized multi-subject video generation. Code and models are available at https://jiazheng-xing.github.io/lumosx-home/.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
The best performance in the CARE 2025 -- Liver Task (LiSeg-Contrast): Contrast-Aware Semi-Supervised Segmentation with Domain Generalization and Test-Time Adaptation
Oct 05, 2025



Accurate liver segmentation from contrast-enhanced MRI is essential for diagnosis, treatment planning, and disease monitoring. However, it remains challenging due to limited annotated data, heterogeneous enhancement protocols, and significant domain shifts across scanners and institutions. Traditional image-to-image translation frameworks have made great progress in domain generalization, but their application is not straightforward. For example, Pix2Pix requires image registration, and cycle-GAN cannot be integrated seamlessly into segmentation pipelines. Meanwhile, these methods are originally used to deal with cross-modality scenarios, and often introduce structural distortions and suffer from unstable training, which may pose drawbacks in our single-modality scenario. To address these challenges, we propose CoSSeg-TTA, a compact segmentation framework for the GED4 (Gd-EOB-DTPA enhanced hepatobiliary phase MRI) modality built upon nnU-Netv2 and enhanced with a semi-supervised mean teacher scheme to exploit large amounts of unlabeled volumes. A domain adaptation module, incorporating a randomized histogram-based style appearance transfer function and a trainable contrast-aware network, enriches domain diversity and mitigates cross-center variability. Furthermore, a continual test-time adaptation strategy is employed to improve robustness during inference. Extensive experiments demonstrate that our framework consistently outperforms the nnU-Netv2 baseline, achieving superior Dice score and Hausdorff Distance while exhibiting strong generalization to unseen domains under low-annotation conditions.
RealisMotion: Decomposed Human Motion Control and Video Generation in the World Space
Aug 12, 2025Generating human videos with realistic and controllable motions is a challenging task. While existing methods can generate visually compelling videos, they lack separate control over four key video elements: foreground subject, background video, human trajectory and action patterns. In this paper, we propose a decomposed human motion control and video generation framework that explicitly decouples motion from appearance, subject from background, and action from trajectory, enabling flexible mix-and-match composition of these elements. Concretely, we first build a ground-aware 3D world coordinate system and perform motion editing directly in the 3D space. Trajectory control is implemented by unprojecting edited 2D trajectories into 3D with focal-length calibration and coordinate transformation, followed by speed alignment and orientation adjustment; actions are supplied by a motion bank or generated via text-to-motion methods. Then, based on modern text-to-video diffusion transformer models, we inject the subject as tokens for full attention, concatenate the background along the channel dimension, and add motion (trajectory and action) control signals by addition. Such a design opens up the possibility for us to generate realistic videos of anyone doing anything anywhere. Extensive experiments on benchmark datasets and real-world cases demonstrate that our method achieves state-of-the-art performance on both element-wise controllability and overall video quality.
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025
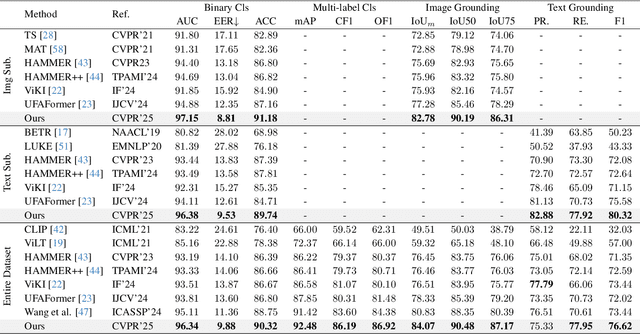
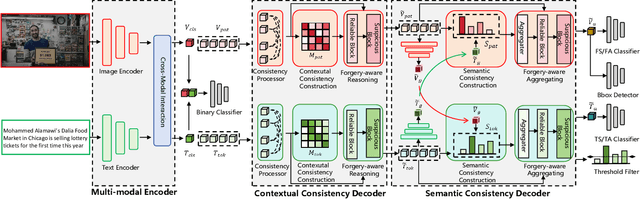
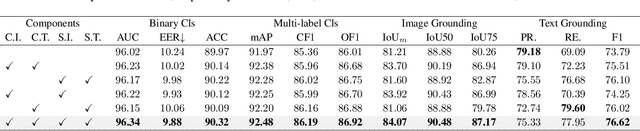
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.
FPSAttention: Training-Aware FP8 and Sparsity Co-Design for Fast Video Diffusion
Jun 06, 2025Diffusion generative models have become the standard for producing high-quality, coherent video content, yet their slow inference speeds and high computational demands hinder practical deployment. Although both quantization and sparsity can independently accelerate inference while maintaining generation quality, naively combining these techniques in existing training-free approaches leads to significant performance degradation due to the lack of joint optimization. We introduce FPSAttention, a novel training-aware co-design of FP8 quantization and sparsity for video generation, with a focus on the 3D bi-directional attention mechanism. Our approach features three key innovations: 1) A unified 3D tile-wise granularity that simultaneously supports both quantization and sparsity; 2) A denoising step-aware strategy that adapts to the noise schedule, addressing the strong correlation between quantization/sparsity errors and denoising steps; 3) A native, hardware-friendly kernel that leverages FlashAttention and is implemented with optimized Hopper architecture features for highly efficient execution. Trained on Wan2.1's 1.3B and 14B models and evaluated on the VBench benchmark, FPSAttention achieves a 7.09x kernel speedup for attention operations and a 4.96x end-to-end speedup for video generation compared to the BF16 baseline at 720p resolution-without sacrificing generation quality.
On Denoising Walking Videos for Gait Recognition
May 24, 2025To capture individual gait patterns, excluding identity-irrelevant cues in walking videos, such as clothing texture and color, remains a persistent challenge for vision-based gait recognition. Traditional silhouette- and pose-based methods, though theoretically effective at removing such distractions, often fall short of high accuracy due to their sparse and less informative inputs. Emerging end-to-end methods address this by directly denoising RGB videos using human priors. Building on this trend, we propose DenoisingGait, a novel gait denoising method. Inspired by the philosophy that "what I cannot create, I do not understand", we turn to generative diffusion models, uncovering how they partially filter out irrelevant factors for gait understanding. Additionally, we introduce a geometry-driven Feature Matching module, which, combined with background removal via human silhouettes, condenses the multi-channel diffusion features at each foreground pixel into a two-channel direction vector. Specifically, the proposed within- and cross-frame matching respectively capture the local vectorized structures of gait appearance and motion, producing a novel flow-like gait representation termed Gait Feature Field, which further reduces residual noise in diffusion features. Experiments on the CCPG, CASIA-B*, and SUSTech1K datasets demonstrate that DenoisingGait achieves a new SoTA performance in most cases for both within- and cross-domain evaluations. Code is available at https://github.com/ShiqiYu/OpenGait.
RealisDance-DiT: Simple yet Strong Baseline towards Controllable Character Animation in the Wild
Apr 21, 2025



Controllable character animation remains a challenging problem, particularly in handling rare poses, stylized characters, character-object interactions, complex illumination, and dynamic scenes. To tackle these issues, prior work has largely focused on injecting pose and appearance guidance via elaborate bypass networks, but often struggles to generalize to open-world scenarios. In this paper, we propose a new perspective that, as long as the foundation model is powerful enough, straightforward model modifications with flexible fine-tuning strategies can largely address the above challenges, taking a step towards controllable character animation in the wild. Specifically, we introduce RealisDance-DiT, built upon the Wan-2.1 video foundation model. Our sufficient analysis reveals that the widely adopted Reference Net design is suboptimal for large-scale DiT models. Instead, we demonstrate that minimal modifications to the foundation model architecture yield a surprisingly strong baseline. We further propose the low-noise warmup and "large batches and small iterations" strategies to accelerate model convergence during fine-tuning while maximally preserving the priors of the foundation model. In addition, we introduce a new test dataset that captures diverse real-world challenges, complementing existing benchmarks such as TikTok dataset and UBC fashion video dataset, to comprehensively evaluate the proposed method. Extensive experiments show that RealisDance-DiT outperforms existing methods by a large margin.